注意:cmd 操作数据库时每条命令后必须加分号,否则会认为命令没有结束不会执行
操作MySQL数据库
创建一个新的数据库
1 | create database 库名; |
删除指定的数据库数据库
1 | drop database 库名; |
| mysql -u root -p密码 | 连接数据库 |
|---|---|
| flush privileges; | 刷新数据库 |
| show databases; | 查看所有的数据库 |
| user 数据库名; | 切换数据库 |
| show tables; | 查看数据库中所有的表 |
| describe 表名; | 显示数据库中的所有的表的信息 |
| desc 表名; | 查看表的结构 |
| exit; | 退出MySQL的连接 |
数据库的列类型
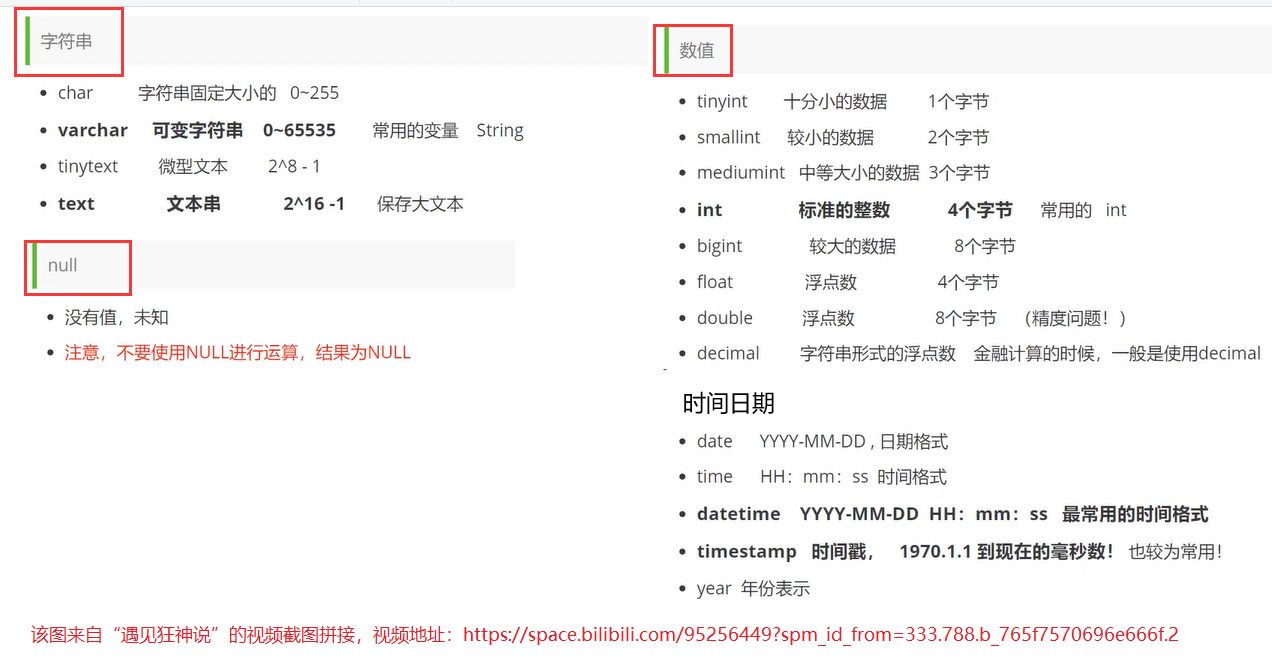
数据库的字段属性
- unsigened: 无符号的整数,声明该列时不能为负数;
- zerofill: 0填充的,不足的位数由0来填充;
- 自增: 通常理解为自增,自动在上一条记录上的基础上+1(默认),通常用来设计唯一的额主键“index”,必须时 整数类型,可以自定义设计主键自增的起始值和步长。
表的基本操作
- 表的常用的修改、删除命令:
常用的修改命令 修改表名 alter table 旧表名 rename as 新表名; 增加表的字段 alter table 表名 add 字段名 列属性[] 修改表的字段(修改约束) alter table 表名 modify 字段名 列属性[] 修改表的字段(字段重命名) alter table 表名 change 旧名字 新名字 列属性[] 常用的删除命令 删除表的字段 alter table 表名 drop 字段名 删除表(存在的表) drop table if exists 表名 - 创建一个新表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15-- IF NOT EXISTS 判断 student 这个表在数据库中是否存在同名的表,如果不存在,就创建:
-- PRIMARY KEY(`id`) 将id设为主键;
-- PRIMARY KEY 主键,一般一个表只有唯一的一个主键;
-- ENGINE=INNODB 设置引擎为INNODB;
-- CHARSET=utf8 设置默认字符集为utf8;
CREATE TABLE IF NOT EXISTS `student` (
id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '000000' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) NOT NULL DEFAULT '月球' COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
MYISIAM、INNODB 引擎
- 所有的数据文件都存在data目录下,一个文件就对应一个数据库。
- 数据库的本质就是文件的存储。
- MySQL 引擎的物理文件上的区别:
·INNODB 在数据表中只有 .fram文件,以及上级目录下的 ibdata1文件
·MYISAM 对应文件有 .frm 表结构的定音文件,.MYD 数据文件(data), .MYI 索引文件(index)。
| MYISAM | INNODB | |
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间大小 | 较小 | 较大,约为两倍 |
|
常规使用操作: ·节约空间,速度加快; ·安全性高,事物的处理,多表多用户操作; |
MySQL 数据库管理
添加外键
注意:删除由外键关系的表时,必须先删除引用该表(主表)的所有表(从表),在删除该表,否则会报错(删除失败)
创建表的同时添加外键
1 | -- 创建 grade 表 |
创建表后单独添加外键
1 | 格式: |
DML语言
添加(insert 语句)
- 单个插入
1
2
3
4
5格式:
INSERT INTO `表名` (`添加字段名`) VALUES ('值');
eg:
INSERT INTO `student` (`name`) VALUES ('夏淼淼'); - 一行多列插入
1
2
3
4
5
6
7格式:
INSERT INTO `表名` (`添加字段名1`,`添加字段名2`,`添加字段名3`)
VALUES ('值1','值2','值3');
eg:
INSERT INTO `student` (`name`,`pwd`,`sex`,`birthday`,`address`,`email`)
VALUES ('jake','123456','男','1999-10-26','爪洼','666666'); - 多行多列插入(每一行插入相同的字段的字段数相等)
1
2
3
4
5
6
7格式:
INSERT INTO `表名`(`添加字段名1`,`添加字段名2`,`添加字段名3`)
VALUES ('值1','值2','值3'),('值1','值2','值3'),...;
eg:
INSERT INTO `student`(`name`,`pwd`,`sex`)
VALUES ('tom','222222','男'),('jake','333333','男'); - 省略字段,给定行号(id),前提是值与表中的字段是一一对应的顺序不可错!
1
2
3
4
5格式:
INSERT INTO `表名` VALUES (行号,'值1','值2','值3',...)
eg:
INSERT INTO `student` VALUES (4,'夏淼淼','333333','女','2020-8-25','火星','159753')5.注意事项:
(1)字段和字段之间,值和值之间用英文状态的“逗号”隔开,字段用 ` ` 引上,值用英文状态的 '' 引上。 (2)字段可以省略,但后面的值必须要一一对应,不能少。 (3)可以同时插入多条数据,values后面的值,需要使用英文状态的逗号隔开,数据组用括号括起来,values(数据组),(数据组),...
修改(updata 语句)
- 单个修改指定属性(如果不添加where判断那么指定列的所有数据都会被修改成将要修改的数据)
1
2
3
4格式:
UPDATE `表名` SET `列名` ='jice' WHERE 主键名=行号
eg:
UPDATE `student` SET `name` ='jice' WHERE id=1 - 修改多个属性
1
2
3
4格式:
UPDATE `表名` SET `列名1`='夏淼淼',`列名2`='123@qq.com',... WHERE id=1
eg:
UPDATE `student` SET `name`='夏淼淼',`email`='123@qq.com' WHERE id=1 - 运算符
操作符操作的返回值是布尔值!条件where 子句常用运算符 操作符 含义 范围 结果 = 等于 1=2 false <>或!= 不等于 1<>2 true > 大于 1>2 false < 小于 1<2 true <= 小于等于 1<=2 true >= 大于等于 1>=2 false and && 1>2&&1<2 false or || 1>2&&1<2 true between...and... 在某个范围内 [1,2]
删除(delete 语句)
1.delete
1 | 格式: delete from `表名` |
2.truncate
1 | 格式: truncate table `表名` |
3.delete、truncate的共同点
delete、truncate 都是删除数据的命令,都不会删除表结构。
4.delete、truncate的区别:
delete 删除数据不改变自增数(需要重启数据库才会使自增数归零。原因:innobd 数据存在内存当中,相当于断电即使。myisam 存在文件中不会丢失。
)。
truncate 删除数据自增数归零。
DQL查询数据
DQL:Data Query Language:数据查询语言。
接下来测试命令时会使用的school数据库的创建和数据的添加命令都在这个文件里,提取码iti3:
https://pan.baidu.com/s/1mA0ghsGKmau0ByF0e891kg
select from
- 查询指定字段:
1
2select `字段` frame 表
* 表示表的所有字段 - 给字段起别名:
1
select `字段` as 别名 from 表
- 给表起别名:
1
select * from 表 as 别名;
- 筛选 select 查询出来的结果中重复的数据,重复的数据只显示一条:
1
select distinct `字段` from 表
连表查询
关于链表查询的理解:链表查询首先要确定要查询的字段都是来自那些表中,然后考虑相关表中的交叉数据的字段,通过这些交叉数据,作为判断依据进行查询。
join 查询时,左右的判断为在编写命令时,表名在join的左右的那一侧,类似于:from 左表 left join 右表
内连接 inner join
inner join 是指交叉数据内容的交际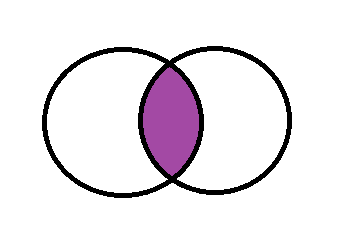
1 | SELECT a.`studentno`,`studentname`,`subjectno`,`studentresult` |
左连接 left join
left join 是指交叉数据内容的交际和坐左表全部的内容,如果右表没有则显示空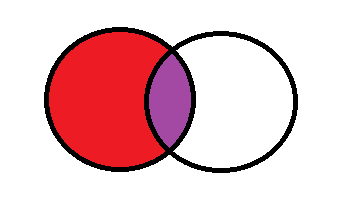
1 | SELECT a.`studentno`,`studentname`,`subjectno`,`studentresult` |
右连接
right join 是指交叉数据内容的交际和坐右表全部的内容,如果左表没有则显示空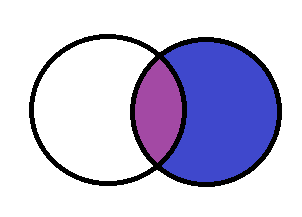
1 | SELECT a.`studentno`,`studentname`,`subjectno`,`studentresult` |
多表查询(两个以上)
当使用两个以上的表进行查询时,应该两两查询,用每次两个表的结果当作一个新表连接另一个表,层层查询
下面是是一个三表查询:
1 | -- 查询学生的学号,姓名,科目名,科目成绩,查询结果根据成绩排序 |
自链接
自连接的理解:就是和自己进行连接查询,给一张表取两个不同的别名,然后附上连接条件。
1 | SELECT a.`categoryName` AS '父栏',b.`categoryName` AS '子栏' |
分页和排序
排序 order by
order by 用来设置排序依据
注意:如果使用where判断需要将where判断写在order by 之前
1. desc 降序排序1 | ORDER BY `studentresult` desc |
1 | ORDER BY `studentresult` asc |
分页limit
为什么要分页?
分页能够缓解数据库压力,并且可以给人更好的体验
1 | 格式: |
子查询
子查询是一种由内向外的查询
1 | -- 查询 高等数学-1的所有考试结果(学号,科目编号,成绩),升序排序 |
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

